
インフォメーション・マートのテーブルをオブジェクト・ストレージで実装する(2)
重要:個人情報や機密情報の使用に関する注意喚起(必ずお読みください)
当検証で紹介している技術やサービスの使用は、読者の皆様自身の判断と責任で行ってください。特に、個人情報や機密情報を含むデータの取り扱いについては、最大限の注意を払い、適切なセキュリティ対策を講じることが不可欠です。
検証や実際の利用を行う際には、常にプライバシー保護の法律、規制、およびベストプラクティスを遵守するよう心掛けてください。また、第三者のデータを使用する場合は、必要な同意を得ること、及びそのデータの使用が法律に準じていることを確認することが重要です。
本ブログや筆者、所属する団体は、紹介する技術を用いて行われるいかなる活動から生じる直接的または間接的な損害に対して、責任を負いかねます。技術を使用することによって生じ得るリスクを理解し、自己の責任で慎重にご活用ください。
本投稿に記載されているクラウド製品は、各社の登録商標です。
ご不明点や懸念がある場合は、クラウドベンダーや専門家に相談することをお勧めします。
当検証の情報を活用することで、読者の皆様が新たな知識やスキルを安全に身に付け、ビジネスでの活用をすすめていただければ幸いです。
前回の投稿「インフォメーション・マートのテーブルをオブジェクト・ストレージで実装する(1)」では、インフォメーション・マートのテーブルをオブジェクト・ストレージで実装する方法とそのメリットについて紹介しました。今回は、Google BigQueryを使用してテーブルにクエリを発行し、実行計画の違い、単体性能及び並列実行時の性能の差異を実際に検証します。
検証概要(振り返り)
検証モデル
検証に使用するデータモデルは、次の通りです。

検証パターンとデータの概要
ファクトテーブルの実装パターン
本検証は、上記のデータモデルのファクトテーブル(オレンジ色のテーブル)の実装をネイティブテーブルやオブジェクト・ストレージを利用した外部テーブルするなどのパターンで性能を検証します。パターンは次の5つです。(前回の投稿から1パターン追加されています。)
| パターン | タイプ | 分割方式 | 分割数 |
|---|---|---|---|
| ネイティブ | ネイティブ | なし | |
| ネイティブ+パーティション | ネイティブ | パーティション | 6パーティション |
| CSV(圧縮なし) | 外部テーブル | ファイル(月+任意) | 1200ファイル |
| CSV(圧縮あり) | 外部テーブル | ファイル(月+任意) | 1200ファイル |
| Parquet(列指向データファイル) | 外部テーブル | ファイル(月+任意) | 1200ファイル |
並列度
並列度が性能に与える影響を検証するため、下記4パターンを実施しました。
- 単体実行
- 4並列実行
- 8並列実行
- 16並列実行
検証方法
検証方法(概要)
検証用SQL
検証で実行するSQLは次の通り。すべてのマスタを紐づけ全件を集計し、客数、売上数量合計、売上金額合計を求めるという内容です。
SQL実行環境
SQLを実行する環境の概要は次の通りです。
| 環境 | Google Cloud Platform Cloud Shell |
|---|---|
| OS | Ubuntu 22.04.4 |
| プログラム言語 | Python 3.12.3 |
| ライブラリ | google-cloud-bigquery future |
| 処理概要 | 配列に定義された複数のSQL文に対し、個別にスレッドを生成し同時実行を行う。 SQLは、データベースのキャッシュを使用しない(use_query_cache=False)のAPI設定の上で実行する。 |
検証用プログラムサンプル
検証結果
実行計画
ファクトテーブルの実装パターン別の実行計画は次の通りです。
- ネイティブ
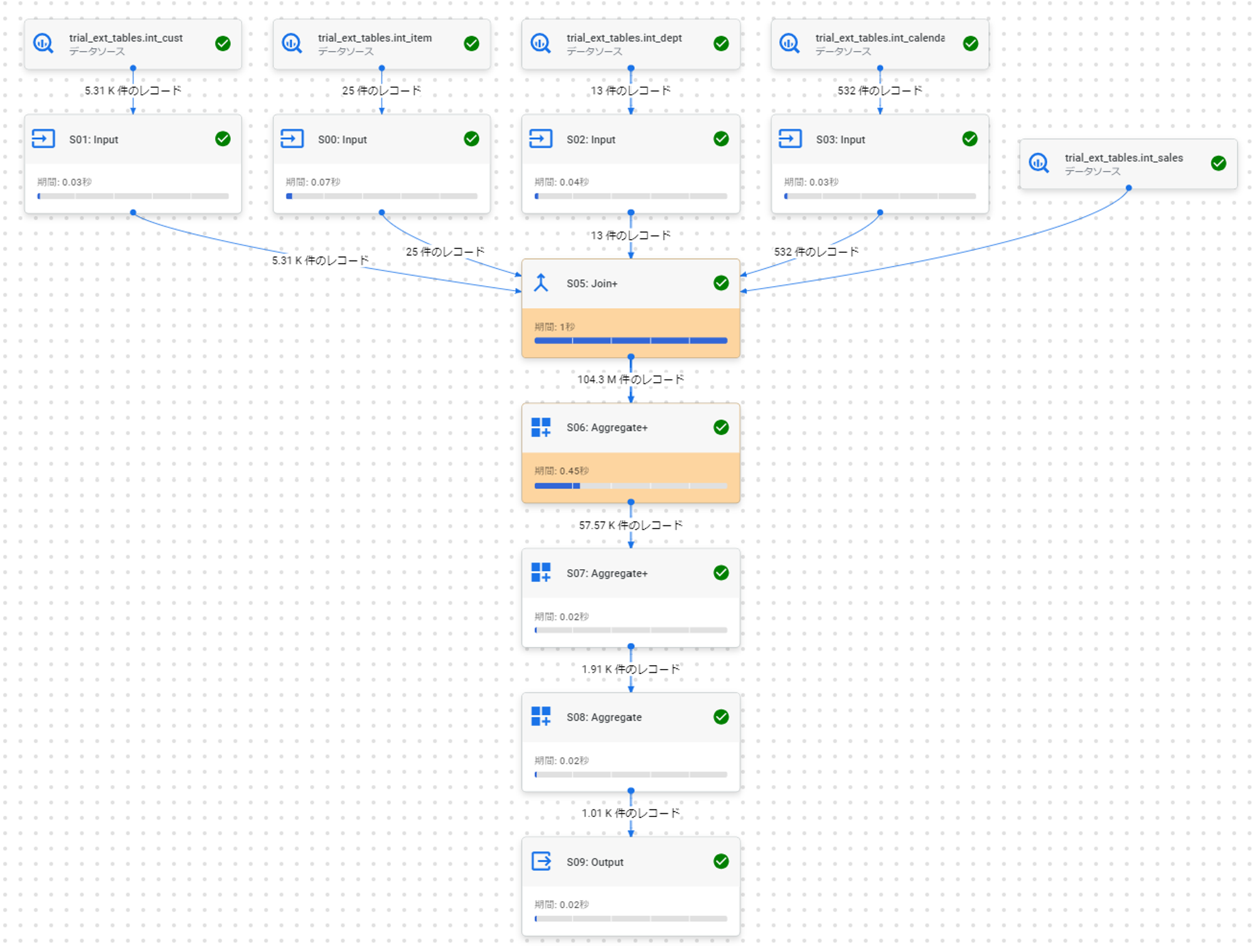
- ネイティブ+パーティション

- CSV(圧縮なし)

- CSV(圧縮あり)

- Parquet(列指向データファイル)

性能検証の結果
また、性能検証の結果は次の通りです。
この結果から、このケースでは次の通りの結果が読み取れます。
- 単体実行の性能は、次の通り。 Parquet > ネイティブ+パーティション > ネイティブ > CSV圧縮 > CSV非圧縮
- 並列実行の性能は、次の通り。 ネイティブ+パーティション > Parquet > ネイティブ > CSV圧縮 > CSV非圧縮
- 並列実行により、いずれのパターンも性能の劣化が認められるが、級数的な劣化は見受けられない。
- ネイティブ+パーティションのパターンは並列実行による性能の劣化が極めて少ない。
また、上述の実行計画のデータを詳細にみると、いずれのパターンも中心の「Join+」のフェーズにスロット時間(BigQueryの計算リソースの単位)の95%以上が消費されていることがわかります。
パターン別消費スロット時間(単位:分)
| パターン | 全体 | Join+フェーズ |
|---|---|---|
| ネイティブ | 42 | 41 |
| ネイティブ+パーティション | 30 | 30 |
| CSV(圧縮なし) | 109 | 108 |
| CSV(圧縮あり) | 105 | 104 |
| Parquet(列指向データファイル) | 33 | 33 |
「ネイティブ+パーティション」以外のすべての実装パターンが同一の実行計画であることを考えると、性能の差異はデータの格納パターンの差異に大きく依存しているものと推察できます。
まとめ
今回は、特定のケースを想定し、インフォメーション・マートのテーブルをオブジェクト・ストレージで実装する方法とその性能を検証しました。実際には、次のような判定基準を用いて、各案件の要件に合った実装方式を選択することが推奨されます。
- データサイズ
- クエリパフォーマンス
- データ更新頻度
- 初期導入コスト
- クエリコスト
- ストレージコスト
- データの形式(構造化/半構造化)
- スキーマの変更頻度
- アクセス頻度
- 運用管理の容易さ